

In data center design and operation, two critical principles are Availability and Reliability. While often used interchangeably, these concepts hold distinct significance in ensuring seamless data center operations.
Availability is at the core of data center operations, focusing on ensuring continuous access to services and resources. It revolves around minimizing downtime and maximizing uptime, guaranteeing that systems remain accessible to tenants whenever needed.
Key characteristics of availability include:
Availability can be referred to by the term “Five 9’s” indicating a system’s long-term average fraction of time in service and satisfactorily performing its intended function, signifying an availability rate of 99.999%.
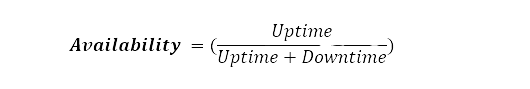
Time units are generally measured in hours, and the time base is 1 year. There are 8,760 hours in none on-leap year. However, Availability does not specify how often an outage occurs over the year.
Reliability, on the other hand, emphasizes the consistency and predictability of a system’s performance over time. It focuses on building systems that deliver consistent service levels without unexpected disruptions or service degradation.
Key characteristics of reliability include:
Reliability is the probability that a product or service will operate properly for a specified time under design operating conditions without failure. Mean Time Between Failures (MTBF) serves as a key indicator of reliability. MTBF is defined as the average duration between two successive failures of a system or component, combining periods when the system is operational (uptime) with those when it is not (downtime).
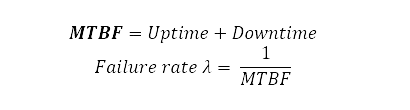
To accurately assess reliability in data center designs, IEEE Std 3006.7-2013 provides several methodologies, including Reliability Block Diagrams (RBD), Fault Tree Analysis (FTA), and Failure Mode Effects and Criticality Analysis (FMECA). Each method offers a unique approach to analysis:
For component failure data, the primary source of failure and repair rates used for the modeling of critical electrical (and mechanical) distribution systems is the IEEE Gold Book, Standard 493-2007 “Recommended Practice of the Design of Reliable Industrial and Commercial Power Systems”.
While availability and reliability represent separate facets of data center design, achieving an optimal balance between the two is essential. Balancing availability ensures uninterrupted access to services, while reliability instills confidence by delivering consistent and dependable performance. By harmonizing these principles, the designer can create resilient data center infrastructures capable of meeting the demands of today’s digital landscape.
Availability gives the average percentage of “uptime” as a measure of the usable time of the unit, while Reliability indicates how long it will operate before it fails.
To measure Availability and Reliability statistics, and for a constant failure rate the following terms are used:

Availability studies can be performed to determine the overall reliability and availability of a data center’s power and cooling infrastructure to test its compliance with the five 9s principle for component failures (excluding failure events due to fire, leak, or impact).
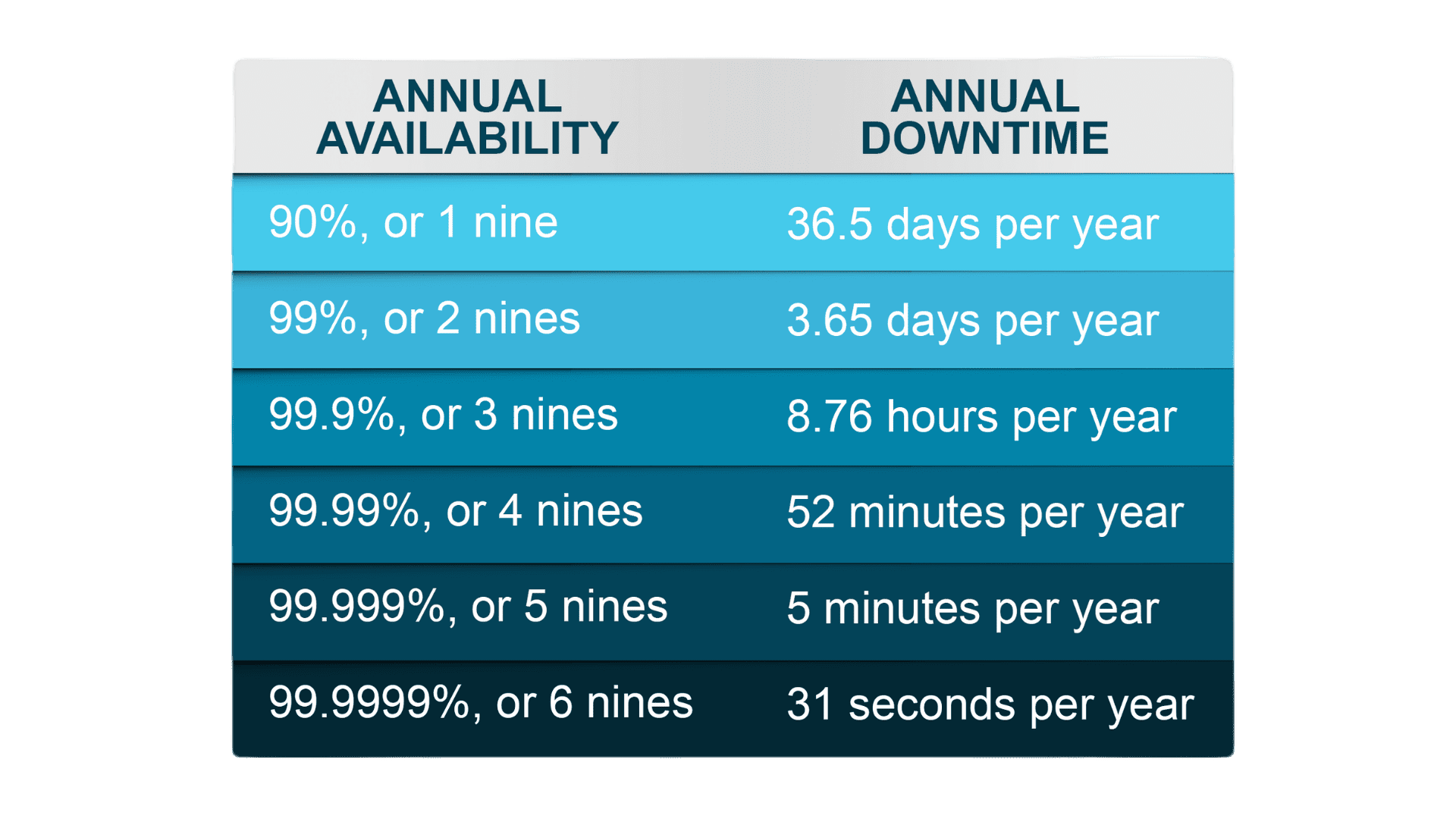
While based on a total of 8,760 hours a year five 9s availability might seem impressive, it still represents 5.3 minutes of downtime per year. Similarly, six 9s corresponds to 32 seconds of downtime per year. However, it’s still far from satisfactory in today’s 7×24 environment where IT power supplies cannot tolerate a disruption of more than 20 milliseconds.
Even when uptime targets such as six 9s are met, it doesn’t eliminate the possibility of experiencing multiple downtimes per year. There can be multiple short outages throughout the year that collectively reach the maximum downtime allowed. This situation, while technically fulfilling the six 9s reliability criteria and falling within most Service Level Agreement (SLA) guidelines, would likely still disappoint most clients. Tenants anticipate continuous, uninterrupted service, highlighting that these uptime metrics might not fully ensure the level of service reliability demanded in today’s digital environment.
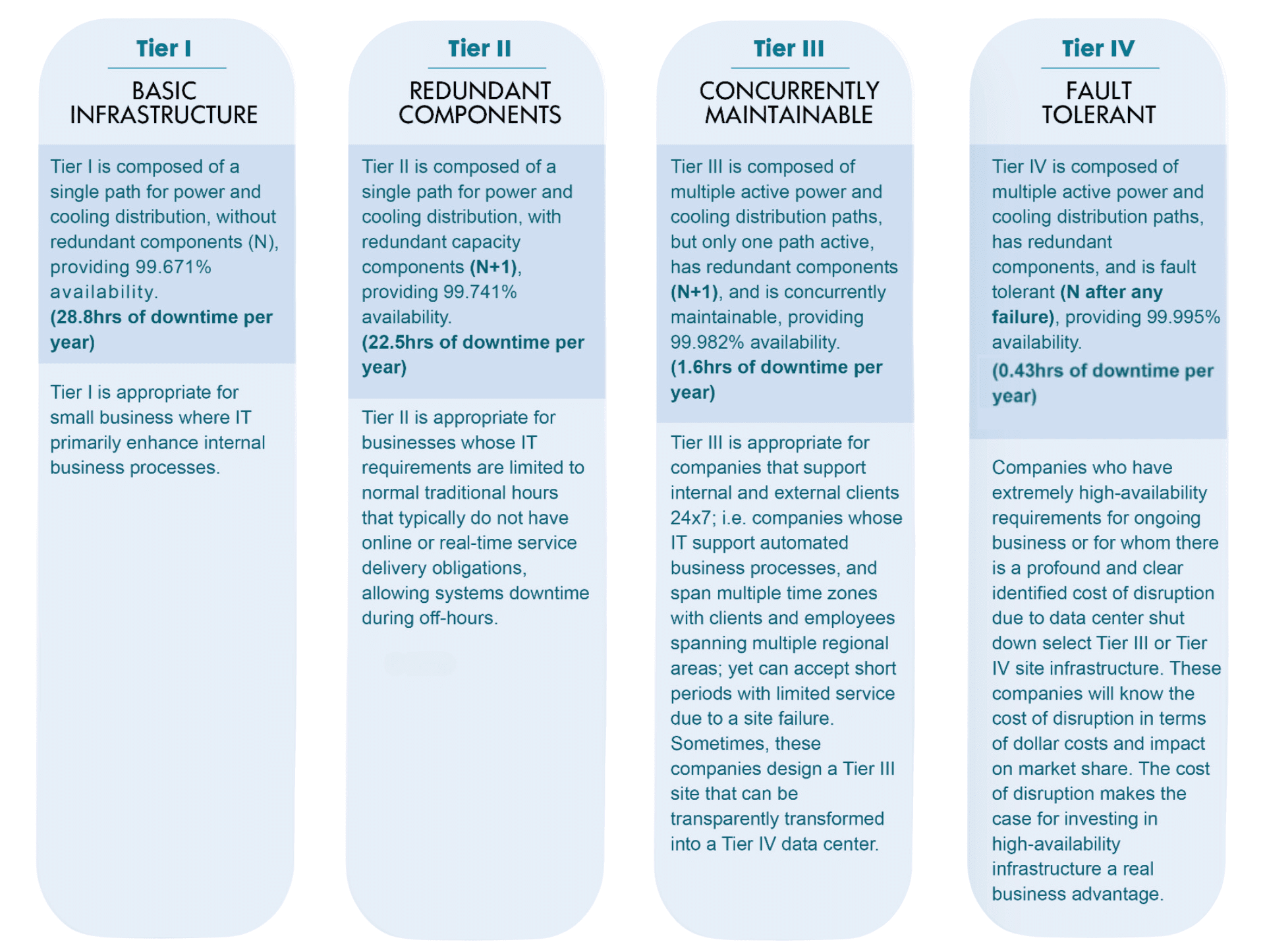
In its initial publication, the Uptime Institute’s Tier Classification Standard provided a four-tier classification approach to data center site infrastructure functionality that addresses the need for a benchmarking standard. The Tier Classifications were created to consistently describe the site-level infrastructure required to sustain data center operations, not the characteristics of individual systems or subsystems.
Keeping all the above in mind, and since Uptime is calculated as Uptime = (MTBF / (MTBF + MTTR)), increasing Availability or Uptime in data centers can be achieved by either:
Since MTBF is inherent/built-in in the overall system components performance (e.g. Chiller compressor), it can fail at a certain point in time (after a certain number of runtime hours) due to wear and tear. MTBF is increased by performing routine preventive and predictive maintenance regularly to the system components to extend the system’s life and/or replace parts before they fail.
Moreover, MTTR is the time needed to repair the equipment after a failure. MTTR can be reduced by:
Reliability, on the other hand, is achieved by eliminating any Single Point of Failure (SPoF) in the system and having Redundancies in the system topology.
Therefore, having redundancies such as:
are ALL mainly intended to:
In other words, having redundancies will allow the system to sustain a fault (or unplanned event) without causing downtime (when all systems are running at partial loads), and will also allow for proactive maintenance (planned event) without having to shut down the IT environment.